Definición
Este algoritmo es muy interesante porque no usa ninguna sentencia if, es decir, no hay ninguna condición, a excepción de los bucles. El algoritmo funciona mejor con una lista larga, de un solo elemento simple: no hay structs, y de números repetitivos. Es mejor que los números no se separen mucho entre sí; por ejemplo, el valor máximo sea de 10, y el mínimo de 1, aunque tengamos 10.000 entradas (o elementos). La desventaja de este algoritmo es la necesidad de almacenar muchos datos en memoria.
Funciona contando el número de objetos que tienen cada clave distinta y el uso de la aritmética en esos recuentos para determinar las posiciones de cada valor clave en la secuencia de salida. Su tiempo de ejecución es lineal en el número de elementos y la diferencia entre los valores clave máximo y mínimo, por lo que solo es adecuado para uso directo en situaciones donde la variación en las claves no es significativamente mayor que el número de elementos. Sin embargo, a menudo se usa como una subrutina en otro algoritmo de clasificación, la clasificación por radix, que puede manejar claves más grandes de manera más eficiente
Seudocódigo
| Significado | |
| Lista principal o de entrada | |
| Lista final u ordenada | |
| Lista de contabilidad o de frecuencia | |
| Valor máximo en A |
El pseudocódigo es el siguiente:
Ordenamiento_por_Cuenta( A, B, k )
1 for i <-- 1 to k
2 do C[i] <-- 0
3 for j <-- 1 to tamaño[A]
4 do C[ A[j] ] <-- C[ A[j] ] + 1
5 // C[i] contiene ahora el número de elementos igual a 'i'
6 for i <-- 2 to k
7 do C[i] <-- C[i] + C[i-1]
8 // C[i] contiene ahora el número de elementos menor que o igual a 'i'
9 for j <-- tamaño[A] downto 1
10 do B[ C[ A[j] ] ] <-- A[j]
11 C[ A[j] ] <-- C[ A[j] ] - 1
1 for i <-- 1 to k
2 do C[i] <-- 0
3 for j <-- 1 to tamaño[A]
4 do C[ A[j] ] <-- C[ A[j] ] + 1
5 // C[i] contiene ahora el número de elementos igual a 'i'
6 for i <-- 2 to k
7 do C[i] <-- C[i] + C[i-1]
8 // C[i] contiene ahora el número de elementos menor que o igual a 'i'
9 for j <-- tamaño[A] downto 1
10 do B[ C[ A[j] ] ] <-- A[j]
11 C[ A[j] ] <-- C[ A[j] ] - 1
Github
Ejemplo
Veamos un ejemplo:
0. C es inicializada asignando todos elementos a cero (pasos 1-2).
1. Empezamos con una lista desordenada, A, de números enteros que se repiten varias veces.
2. C es asignada valores que representan la cuenta de cada elemento de A (pasos 3-4). El índice de C representa el elemento de A: 0 unos, 0 doses, 3 treses, y 2 cuatros.

 5. El elemento de C usado para ordenar B es restado 1 (paso 11).
5. El elemento de C usado para ordenar B es restado 1 (paso 11).
6. B es asignada otro valor en orden (pasos 9-10), con j = 4.

7. C es nuevamente restada 1 al elemento recién usado (paso 11).
8. B es añadida otro número en su propio sitio, con j = 3.
 9. Se repite paso 11.
9. Se repite paso 11.
10. Pasos 9-10, con j = 2.
 11. Paso 11.
11. Paso 11.
12. Pasos 9-10, con j = 1.



1. Empezamos con una lista desordenada, A, de números enteros que se repiten varias veces.
2. C es asignada valores que representan la cuenta de cada elemento de A (pasos 3-4). El índice de C representa el elemento de A: 0 unos, 0 doses, 3 treses, y 2 cuatros.

3. C es asignada a cada elemento la suma de su valor y el del elemento anterior (pasos 6-7); por ejemplo, C[3] = C[3] + C[2], etc.. Esto sirve para saber en qué índice acaba el bloque de números repetidos: C[3] = 3 => bloque de treses acaba en índice 3, C[4] = 5 => bloque de cuatros acaba en índice 5.
4. B es la lista ordenada de A. Es asignada el primer número ordenada: 3 (pasos 9-10), con j = 5.

6. B es asignada otro valor en orden (pasos 9-10), con j = 4.

7. C es nuevamente restada 1 al elemento recién usado (paso 11).
8. B es añadida otro número en su propio sitio, con j = 3.

10. Pasos 9-10, con j = 2.

12. Pasos 9-10, con j = 1.
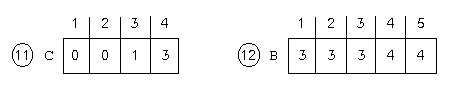
13. Ningún elemento de C tendrá un valor negativo.
14. j = 0, por lo tanto se sale del bucle for. B da lugar al resultado, que es el ordenamiento de A:


